- Published on
363 Star!开箱即用的增强版 ChatTTS 一键整合包
- Authors

- Name
- 三金得鑫
- 掘金
- 掘金
上一篇玩儿了一下 AI 语音大模型 ChatTTS,从部署到使用再到接入 Dify(虽然能接入,但是只能展示生成的文件路径)整个过程都很顺畅。
不过在部署上,前置准备工作还是有一些多的,要安装各种依赖、拉取项目源代码以及创建并激活虚拟环境等等。为了方便部署,就有大佬开发了一款 ChatTTS 本地离线整合包并开源到了 Github 上——ChatTTS-Enhanced。
在 ChatTTS-Enhanced 项目中提供了不同系统(Windows 和 MacOS)的安装包,只要傻瓜式进行安装即可。
安装后双击打开,就可以快速启动增强版的 ChatTTS 了~~
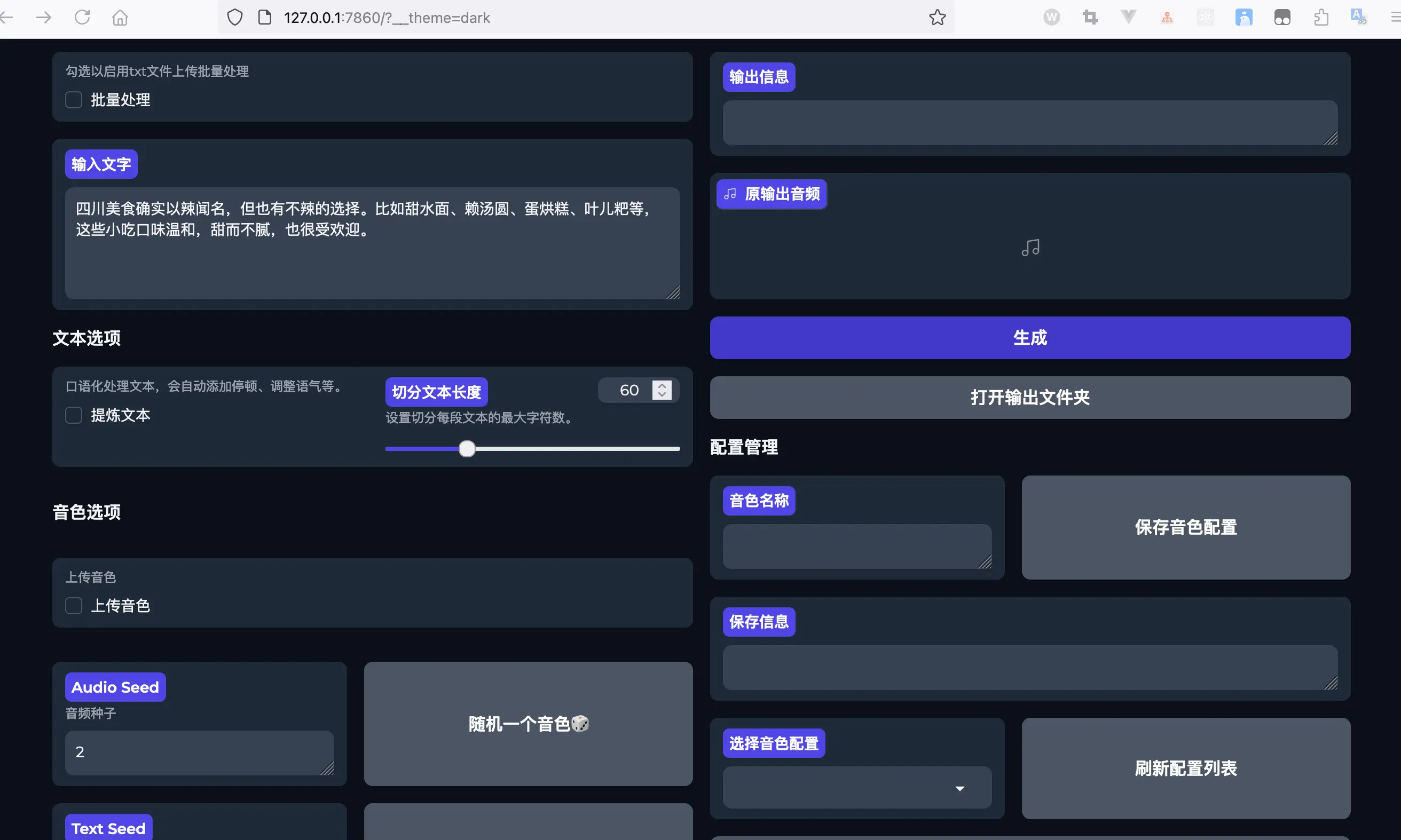
目前已经更新到了 V3 版本,这个版本中的亮点如下:
- 音质增强/降噪解决Chat-TTS生成时的噪音问题。
- 支持多TXT、SRT文件批量处理。
- 支持长文本处理,支持中英混读。可自定义切割长度。
- 支持导出srt文件。
- 支持调节语速、停顿、笑声、口语化程度等参数。
- 支持导入ChatTTS Speaker音色。详情看帮助。
- 支持储存音色配置与选项配置。方便管理。
那长文本效果具体如何呢?我们一起来听一下:
语音占位
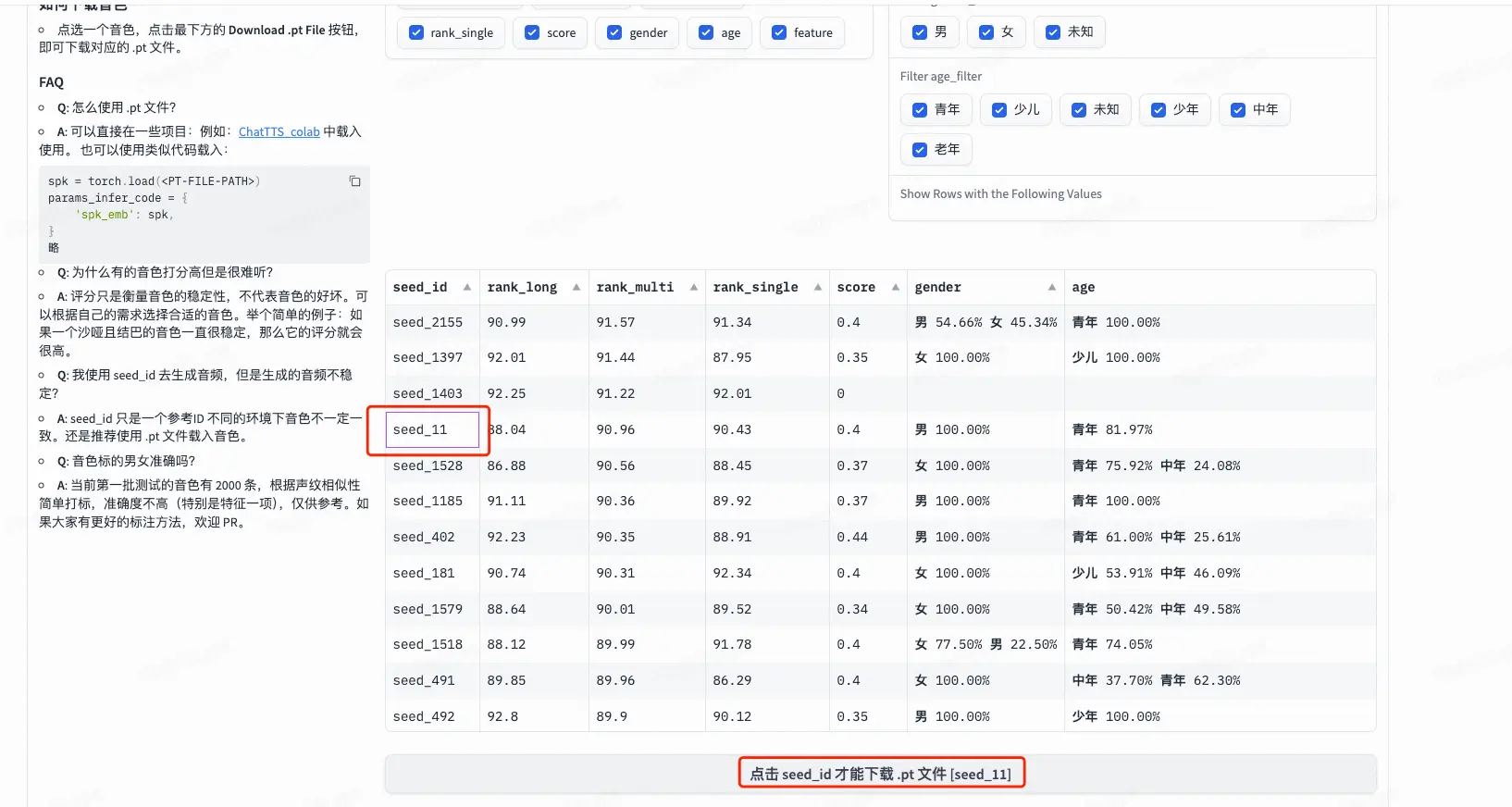
关于音色来说,如果我们想指定一个音色进行生成,可以先到音色库中找一个比较中意的,然后下载对应的 pt 文件:
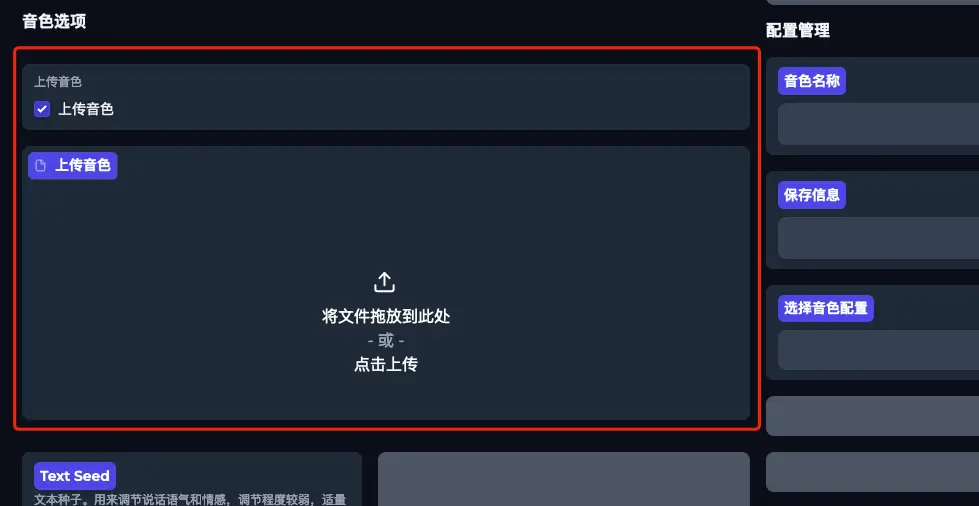
将下载好的文件在这里进行上传即可:
这一版本的整合包需要以及配置才可以运行:
- Windows: 需要 Win10/11,支持 CPU 和 GPU
- MacOS:不管是 M 芯片还是 Intel 芯片,系统版本必须在 10.13 以上
显存在不开启音频增强的情况下需要最低 4G 的配置,对于 Mac 来说,作者目前只做了 CPU 的适配,因为显存这块说是还有些问题。
如果自身及其配置比较低,作者还贴心的提供了云端一键部署的功能,感兴趣的朋友可以在 B 站搜索「嘟嘟实验室」,除了语音整合包之外,还有其他很多好玩儿的整合包。